

In the last typos-detection-posts I worked out the POS transition matrices for 3 classic books, to serve as comparisons of “exemplary writing” to compare to my own rubbishy style matrix. What I have done now is done a bit of post-processing on those matrices to try and compare them. To be honest statistics and matrices do my head in, so I have done my best, rather than produce something useful.
Comparing two matrices is not as trivial as I thought (what is, right!). I googled “How do I compare two matrices” and get the following pointers:
- You can calculate the distance between matrices. There are (more than) a couple of ways to do this, I think, but the most understandable to me is calculating the norm of the difference
- You can do a correlation analysis.
- You can produce a similarity matrix
I have done all of the above to cross-compare the four matrices I have, to see if I get anything useful. Excuse me for what follows: my explanation for what numbers I have crunched.
Matrix Distance
This lecture paper explains matrix norms pretty clearly:
The norm of a matrix is a measure of how large its elements are. It is a way of determining the “size” or “magnitude” of a matrix that is not necessarily related to how many rows or columns the matrix has.
Perfect! And so if I work out the norm of the difference between matrixes, 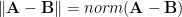 , this will be me a single scalar which is an indication of the similarity between
, this will be me a single scalar which is an indication of the similarity between 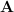 and
and 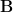 (as the norm/distance gets closer to zero).
(as the norm/distance gets closer to zero).
Of course, there is more than one way to skin a cat and as the lecture paper I linked to before sets out, there a few different norms too. I chose:
- the Frobenius norm, initially because it sounded the best (literally), and;
- the L2-norm.
Now, were I thinking about the magnitude of a matrix, or more simply a vector in space, I would default to applying Pythagoras’s theory. In matrix-talk this the Euclidean norm. What threw me to start with was that depending on where you look, both the Frobenius and L2 norm both get called the Euclidean norm, and in matrix notation both are slightly mind boggling and look nothing like 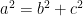 . Anyway, after getting my brain in math-mode I got there in the end:
. Anyway, after getting my brain in math-mode I got there in the end:
Frobenius Norm

Ferdinand Georg (love the no e) Frobenius
A clear example here. And here is it in Math-Speak:

In my eyes, this looks most like Pythagoras right? The lecture paper I linked to before, I think, equates the Euclidean norm to the Frobenius norm. The matrix notation for it is a bit more convoluted, which was what was making me confused:

Turns out that:
 was (the sum of the diagonals)
was (the sum of the diagonals)- In my real number square matrix condition , and;
- I just stick in there with as one of my probability matrixes and as the other.
 was (the sum of the diagonals)
was (the sum of the diagonals) , and;
, and;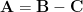 in there with
in there with  as one of my probability matrixes and
as one of my probability matrixes and Even easier (after I had gone and written my own code to work it out Grrrr!) I found that the JAMA matrix library I am using has a method (Matrix.normF()) already. Here is my implementation anyway, just because:
[code]
public static double calc(Matrix A, Matrix B){
Matrix C = A.minus(B);
Matrix Ct = C.transpose();
return Math.sqrt((Ct.times(C)).trace());
}
[/code]
Incidentally (but good to know?) it turns out Ferdinand Georg Frobenius was a bit of a Smarty-Pants
The L2-Norm
This is more of the same really, except rather than adding ALL the squares in the matrix together and taking the root of the sum (which is what the Frobenius norm does) the L2-Norm takes the Euclidean length of each column (vector) and then adds them all together. Quite why you would does this, I am none the wiser. It gives a different value to the Frobenius norm (of course) and it can be shown by maths-heads to always be smaller than (or equal to?) the  .
.
By this stage I had wised-up. The JAMA matrix library has it already as Matrix.norm2().